Platooning Demonstrator with Deep Learning and Computer Vision
Originally envisioned as a demonstrator for the Bosch AI CON 2019, the platooning system consists of two cars, a leading car and a following car. The leading car can be driven manually using a PS4 controller and the following car will autonomously follow the leading car.

In addition to this, the system currently is also capable of Object Tracking, Velocity Estimation by Optical Flow Visual Odometry and Monocular Depth Estimation.
Abstract
A sample output of what the following car sees in its camera stream is shown below.

Object Detection
The following car utilizes an Object Detection DNN, amongst other things, to identify and localize the leading car in its input camera stream with a bounding box. The object detection architecture is an Inception V2 Convolutional Neural Network with a Single Shot Detector (SSD) for the actual object detection.
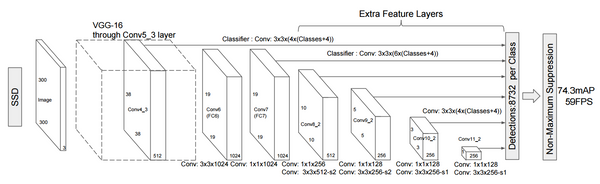
Information about the SSD can be found at https://arxiv.org/abs/1512.02325. The VGG-16 part is replaced by the Inception CNN.
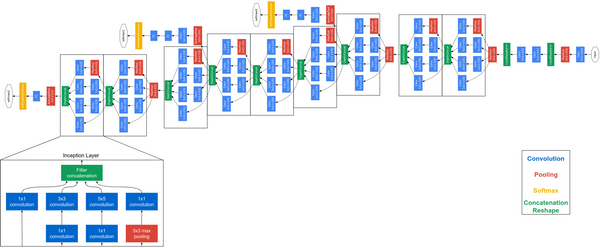
More details about the Inception V2 architecture can be found at https://arxiv.org/abs/1512.00567. The Inception architecture was chosen for its good trade-off between speed and performance when compared to other models that are optimized to run on embedded systems. The comparison can be found at https://arxiv.org/abs/1611.10012.
*Transfer Learning* was used in order to repurpose a SSD Inception model trained on the COCO (Common Objects in COntext) dataset, modified to detect a single class of objects - the leading car. Let us call this _custom_ object detection. We use images such as the ones shown below with the leading car in different environments, labelled by a bounding box for the training.

Tensorflow provides a pre-trained model of this architecture. For information on the custom object detection training routine, you can refer https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/training.html. The retraining of the model is done on a Google Colab notebook to make use of the free (!) Tesla GPU and 64 GB RAM. The model can be fully or partially retrained based on performance needs. If privacy or data security is a concern, the notebook can be run on a local machine.
The Inference of the model is accelerated by TensorRT, details of which can be found at https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html.
Object Tracking
The detected leading car is assigned an ID in order to identify it as a member of a series of platooning cars. If the leading car steers off frame and then reappears, the rudimentry tracking algorithm is capable of identifying that the car that is back in frame is the car with the same ID. It uses mathematical concepts such as maximizing the IOU (Intersection Over Union) metrics between bounding boxes in neighboring frames.This is made possible by, amongst other things, a Kalman Filter. The implementation details can be found at https://arxiv.org/abs/1602.00763.
![]()
Velocity Estimation
Optical flow methods utilize the differences in pixel intensities across consequent frames to calculate apparent motion.

This fundamental method is usually used to determine the flow of an object across a frame, but gave me an idea that it can also be used to used to calculate self velocity (velocity of the following car) by considering the car itself as the moving object. The function calcOpticalFlowFarneback from OpenCV that facilitates this is the based on the paper found at https://rd.springer.com/chapter/10.1007/3-540-45103-X_50.
Depth Perception
This is an effort to be able to sense depth information (monocular) from a 2D camera. Implementation details can be found at https://arxiv.org/abs/1806.01260.

A rudimentary use case of this for obstacle detection has been implemented. The depth perception window displays the observed depths of the environment in a grayscale map (0-255, normalized). A grayscale pixel value of 0 would indicate the object being further away and a grayscale value of 255 woud indicate an object being the closest. Based on this, a horizontal grid of so called superpixels (cool name, right?!) is defined. The averaged grayscale value within these superpixels is noted and based on this a decision is made as to whether an obstacle is detected or not. A predefined threshold turns the superpixel window red when an obstacle is detected.
Working Principle
The area of the bounding box generated fromt the object detection determines the speed at which the following car keeps up with the leading car - the smaller the area, the further away the leading car is, requiring a larger acceleration and vice versa.

The following car is also designed to maintain a fixed safe distance to the leading car based on the bounding box area. The vertical separator divides the frame into two halves and the centroid of the bounding box and its position along the x axis determines the steering angle of the following car.
The camera system also includes a pan-tilt mechanism, which is tasked with orienting the center of the camera to the center of the bounding box which in turn is used to set the steering angle. This provides an additional degree of freedom to the following method and helps when there are relatively sharp turns made by the leading car.